实战数据科学: 如何利用 sklearn 轻松上榜 Kaggle 入门 NLP 竞赛
· 阅读需 7 分钟

引子
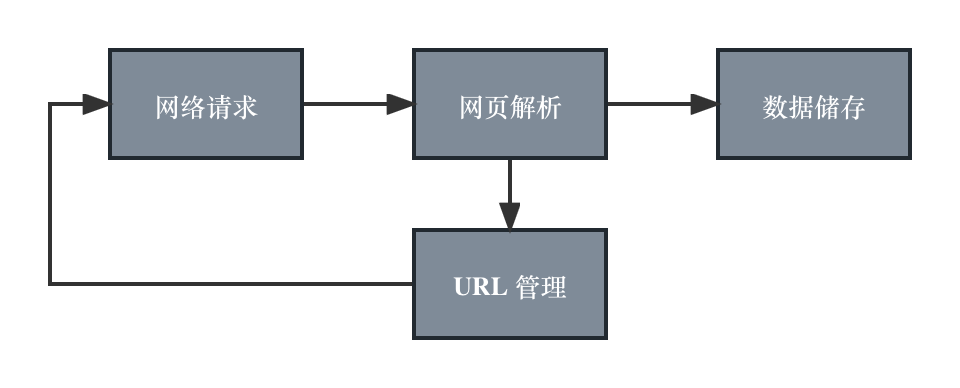
Kaggle 是一个面向数据科学家、机器学习工程师和数据分析师的在线社区和数据科学竞赛平台,上面有很多带有奖励的数据科学竞赛(Competition)以及数据集(Dataset)。Kaggle 社区在数据科学领域非常出名,很多互联网业界大厂也在上面发布有奖竞赛,竞赛金额从几万到百万美元不等。本文介绍的是最近参与的 Kaggle 一个入门 NLP 竞赛,没有现金奖励,但可以学习到 NLP 相关的机器学习知识。
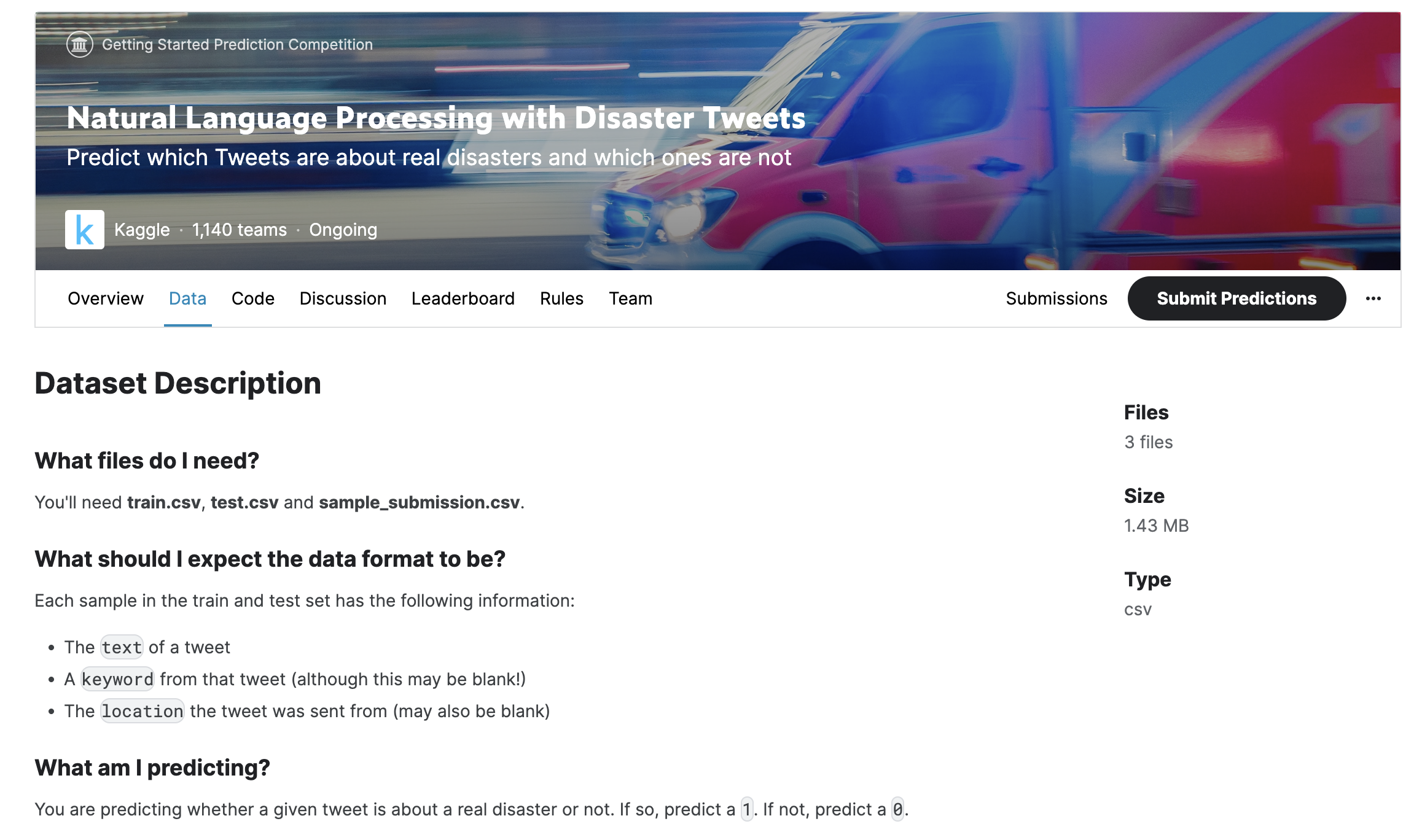
竞赛简介
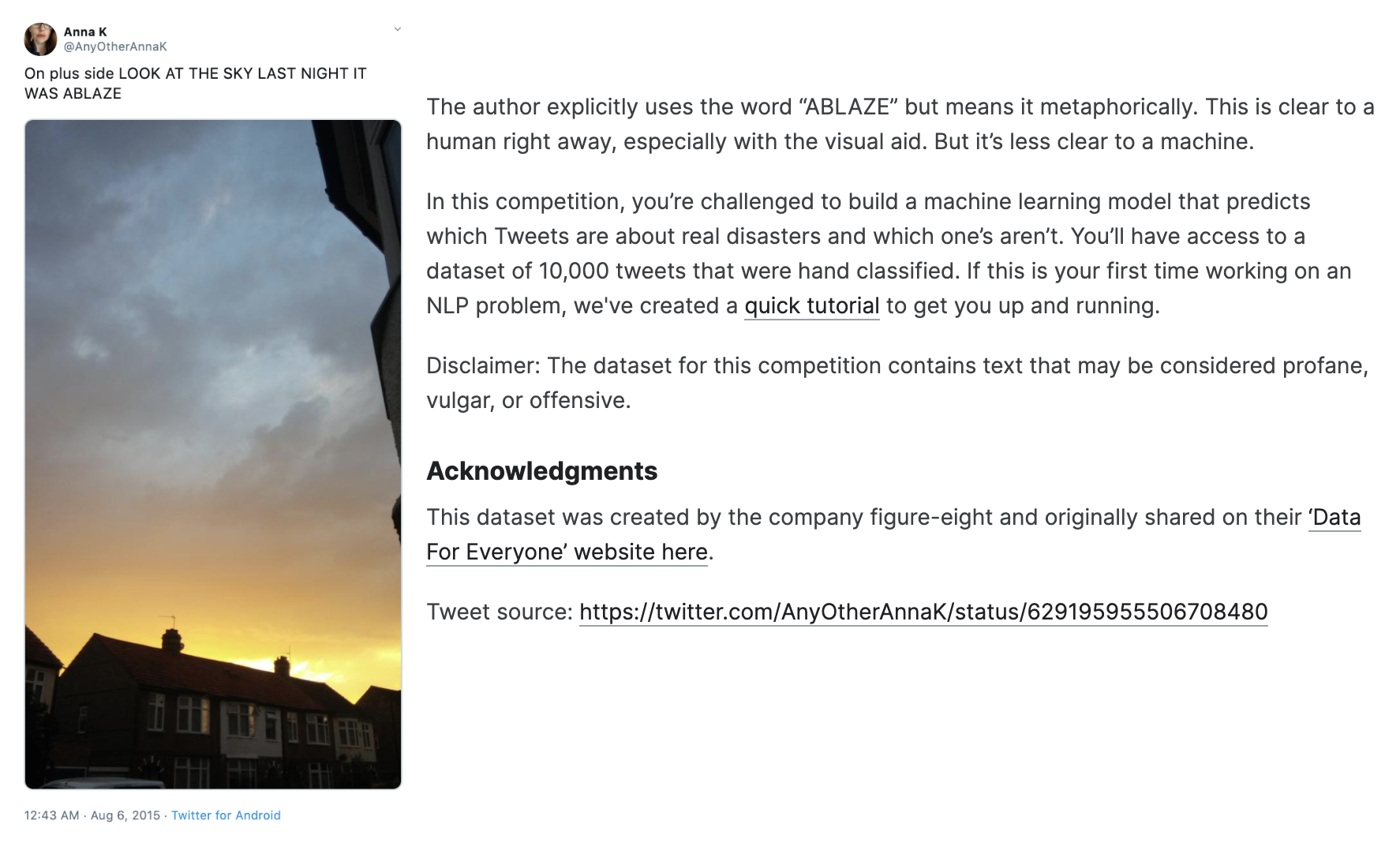
这个数据科学竞赛是希望竞赛参与者通过给定 Twitter 上的一条推文(Tweet),来判断推文是否是关于一场真实的灾害(Disaster)。下图是某一条推文的情况,推文中有 "ABLAZE"(燃烧的)关键词,预示着该推文是说有房子燃起来了。