从作坊到工厂:我在 AWS 峰会看到的智力工业化


亚马逊云科技中国峰会,2026 年 6 月 23–24 日,上海。
2026 年 6 月,我在亚马逊云科技(AWS)上海峰会上做了一场分享,大概是全场"最不性感"的一场。一上来我先澄清了一句:我们的 Nova,不是 Amazon 那个 Nova。我幻灯片上的 Nova,是我在 HP 带队做的一个内部平台;全场其他人挂在嘴边的 Nova,才是亚马逊的前沿大模型。台下笑了。一个撞名的小玩笑,却也恰好划出了这篇文章要讲的那条线——接下来的时间里,我讲的是任何主论坛都懒得碰的东西:我们怎么把一套报表系统,从 Power BI 搬到了 Amazon Athena 加 Apache Iceberg 上。那是个三十分钟、300 级的进阶专题,排在六楼,离楼下的人群远远的。

会场楼层导览:专题演讲(包括我那场)在六楼,主论坛在五楼,展厅在楼下。
而一楼的展厅,卖的全是"性感"的另一面。宇树(Unitree)的人形机器人(humanoid robot)在灯光下伸手抓取;一只标价 ¥9,999 的灵巧手(dexterous hand),冲着镜头比了个耶;一块屏幕上,一群编程智能体(coding agent)全程没人插手,自己把软件交付了,另一块屏幕上,AI 把一段足球比赛录像拆成了战术和球员指标。聚光灯下,智能正学着感知、学着创造、学着在物理世界里行动。

楼下一楼的展厅:人潮都在这儿。
这个反差,就是这篇文章的论点。过去两百年,产出是跟着人头走的——想多干,就得多招人。AI 正在掐断这条线:产出开始靠基础设施(模型、算力、数据)撑着,而不再死死绑在人力上。这就是智力的工业化。和第一次工业革命一样,最后赢的不会是手握最炫机器的人,而是给这些机器铺好地基的人。我那场"无聊"的迁移就是个缩影:让报表变好用的,不是换了个更聪明的模型,而是把脚下的地基换了——刷新从 4–6 小时压到 1 小时;而原本只能盯着看的报表,如今成了谁都能用大白话直接发问的数据。
所以这篇文章,会从地基往上写。先看展厅里被围观的三道前沿——会感知、会创造、会行动的机器;再看撑着这三样的那一层,也就是我专程跑去上海讲的那件事:决定它们到底能长多高的数据底座(data foundation)。
知识工作,至今没有自己的工厂
提起第一次工业革命,人们记住的是蒸汽机。但它真正厉害的地方更隐蔽:它把产出和人力肌肉之间的捆绑,一刀斩断了。在那之前,想多织布,就得让更多织工坐到更多织机前——产出和人手,是绑在一起涨的。工厂打断了这种绑定。产出转而靠资本和基础设施说话——动力、机器、铁路——织工自己的手艺,反倒没有他身处的那套系统重要了。生产不再随人头扩张,而是随他们脚下那座厂房扩张。
知识工作,至今没等来这一刻。想多交付软件,就多招工程师;想多产出分析,就多招分析师;想多接咨询,就多招顾问。产出死死跟着人头走——一家咨询公司的收入,说到底就是计费工时,还有什么生意比它更被人头绑死?珍妮纺纱机问世两个半世纪了,"靠脑子吃饭"这件事,依然停在作坊阶段:靠几双熟练的手,一次干一件活。
如今,AI 对这个作坊做的,正是当年工厂对织工做过的事。我以前就写过,LLM 与其说是一件新工具,不如说是一场新的工业革命——而它的标志,仍是那条被斩断的线。一群编程智能体想多交付,靠的不是多招人,而是多给算力、多给上下文;一条感知管线想多"看见",靠的不是扩编,而是多喂数据。产出正在和人头脱钩,转而绑到基础设施上:模型、算力、数据。这就是智力的工业化——而且它已经在发生了。
有一块板,主论坛轻轻带过了——不是没提,是没停下来讲。这届峰会的主题词,就是 Agentic Now, Go Build,主舞台也照着这个调子来。亚马逊云科技亚太区联席总裁储瑞松给这一刻定了调:AI Agent,他说,正“逐步成为新一代生产关系的主体之一”。基础设施没少谈,但谈的都是智能体那一层的基础设施——屏幕上那张架构蓝图,整整五层:最上面是 Agent 应用,往下是 Agentic 平台(运行时、记忆、工具、编排),再往下、正卡在中间的,是一层“数据与知识”,写着 RAG、向量数据库(vector database)、数据治理(data governance),然后才是模型,最底下是芯片。数据并没有缺席——它是清清楚楚的一层;另一张片子甚至直接写着“数据是护城河”。可然后呢,所有篇幅都给了它上面那两层。这就是那个信号。就算 agent 真成了新主角,每一次工业化,真正决定胜负的,从来不是最炫的那台机器,而是它脚下那块地——铁路真正成就的是握着铁轨的人,不是站在一旁看哪台机车更快的人。轮到智能,脚下这块地也是三块板拼的,三块并不等值:算力是按小时计费的大路货;模型一季一季地收敛,慢慢都长成了一个样。真正难复制的那一块——会越用越值钱、归你所有、能顺着你的业务长——是数据。是数据底座。

主舞台上那张五层蓝图:顶上是 Agent,往下是 Agentic 平台,中间是清清楚楚标着的“数据与知识”层——它在,也标了名,只是没占到台上多少篇幅。

展厅里 Snowflake 的「AI Data Cloud」——数据这层不是没人扛旗,只是没成为主论坛的头条。
这正是我专程跑去上海讲的那个不性感的观点:到了智能体时代,数据底座决定了它上面一切的天花板。模型再聪明,也救不了一个喂进去全是脏数据、没人治理、根本查不动的应用;反过来,底座喂得好,一个平庸的模型也能显出几分本事——这一点,我之前专门写过一篇。所以在展厅里,真正值得问的,从来不是"这些机器有多聪明",而是"它们脚下踩的是什么"。机器满场都是——学着感知、学着创造、学着行动。我们一台台看过去,然后,低头看它们脚下。
感知:把世界变成数据
先说展厅里最好玩的一个:一个"看球"的 AWS demo。喂它一段比赛录像,它能把整场球拆成战术和每名球员的技术指标——谁在哪儿逼抢、哪条传球线路被扯开、某个球员这九十分钟站位怎么挪——靠的是计算机视觉(computer vision,CV),再加一个能把画面"说成人话"的视觉语言模型(VLM)。

足球 demo:上半,计算机视觉给每个球员套上追踪圈;下半,2D 战术视图加球员数据卡,把一场球变成了数据。
真正聪明的地方,不在于模型"看得见"——这道坎,如今的前沿视觉模型轻松就迈过去了。聪明的是,这条管线拿"看见"做成了什么:它把九十分钟一团乱的视频,变成了一行行结构化、查得动的数据。把球场换成工厂产线、零售货架、医院病房,套路一模一样——所谓感知的工业化,就是把杂乱的感官信号,收拾成你存得下、查得着、还能照着去做事的数据。模型是大路货;把"看到的"沉淀成靠谱数据的那条管线,才是真功夫。
第二个 demo 把这层意思说得更透,因为它不光要听懂,还得照着去做。AWS 展示了一套车上的端云协同(device-cloud collaboration)语音助手。在车端,你说的一句话先被转成 embedding,拿去跟已知意图比对:有把握认出来的,本地当场执行;拿不太准的,交给车上的小模型(SLM);只有真正没见过的,才上云、丢给前沿大模型——Amazon Nova on Bedrock。一道 0.97 的置信度门槛,决定一句话走哪条路。
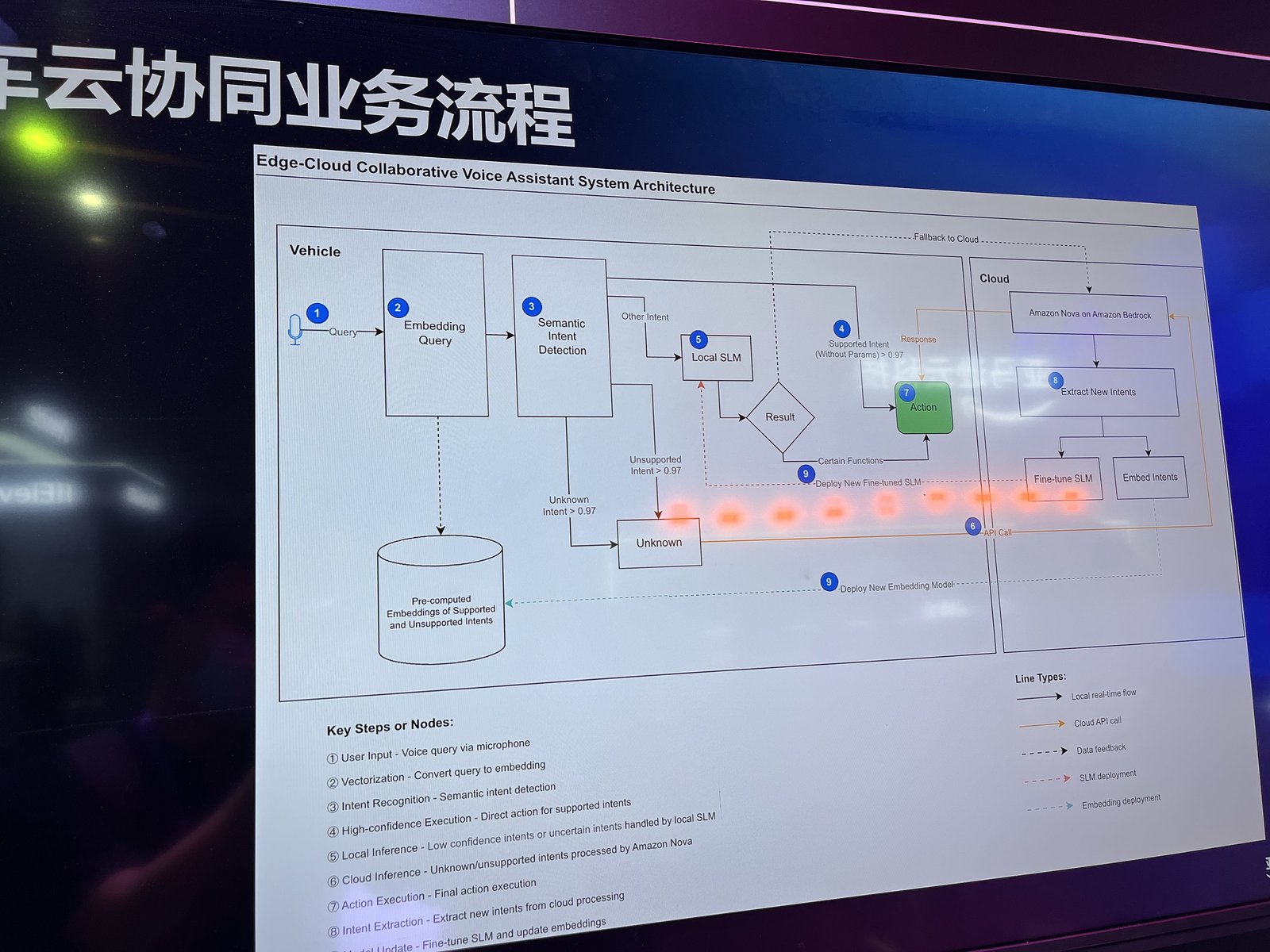
车云协同语音助手的完整架构:车端就地处理已知意图,只有未知的才上云交给 Amazon Nova,云端再微调车端模型、部署回去——那条飞轮。
让它不止是个 demo 的,是底下那条回路。每一句车端搞不定的请求,都变成了数据:到了云端,新意图被拎出来,车上的 SLM 拿去微调(fine-tune),embedding 重新算过,改进后的模型再推回整个车队。系统就这么从自己的失败里——从自己跑出来的那点"尾气"里——越变越聪明。这时候,感知就成了一个飞轮(flywheel),而转动飞轮的,是数据。记住这个画面:它是这篇文章全部论点的一个缩影,下一层我们还会撞见它。
两个 demo,说到底是一回事。无论交出来的是一份球赛洞察,还是行驶中那辆车里的一个动作,一台会感知的机器到底值多少,全看它能不能把感知到的东西,沉淀成结构化、可信、查得到的数据。看见、听见,如今都是大路货;把它们落成数据,才是护城河(moat)。如果说感知是把世界变成数据,那下一道前沿,就是把想法变成成品。
创造:一个人,就是一支队伍
展厅里最抓人的,是一块终端屏幕。AWS 演的是一个"Kiro Swarm"——一个人、一台笔记本,指挥着一整张被实例化成 agent 的研发组织架构图:架构、后端、前端、运维、测试、评审,连项目经理和产品都有。每个 agent 占一个窗格,状态在"思考""干活""深度工作"之间跳;它们在一个共享的团队频道里彼此 @、互相收听,活像一支真团队盯着 Slack。幻灯片上的话很直白:把规范驱动开发(spec-driven development)搬进团队协作——自治 agent 全程无人介入,把一个需求一路做到代码提交,扛得住长任务、跨得了多个仓库。
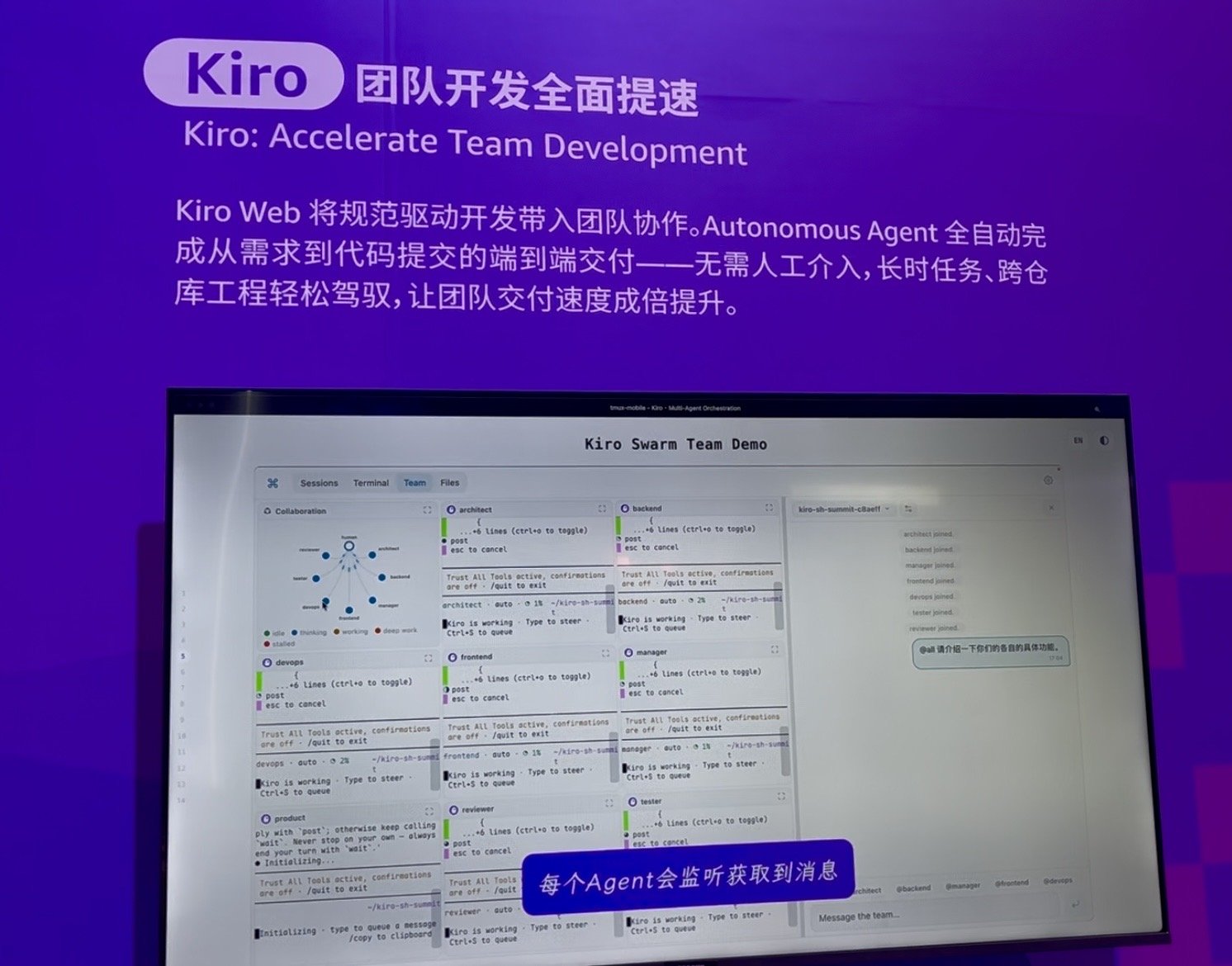
Kiro Swarm 演示——一个人指挥一整张 agent 组织架构图,它们在一个共享频道里互相交谈。
这就是把论点摆上了台面。这张组织架构图不是招来的,是实例化出来的。想多交付,操作者不是去加人,而是去加 agent、加上下文。一个人、一副键盘,指挥出一整支队伍的产出——这是我那几天见到的、"产出和人头脱钩"最干净的一个样本。
而且不止是软件。隔几步就摆着 Ki-Board:一个写着 For Kiro Buddies 的小盒子,有几枚按键、有一块小状态屏,还有一只当电子宠物的幽灵吉祥物。一位 AWS 工程师用 Kiro,两天就把它从头做到尾——选硬件、写固件、设计并打样电路板、建外壳模型、3D 打印外壳。不只是队伍横向铺开了;连"造一个东西"的整条栈,软硬件一起,都坍缩到了一个人加一个 agent 身上。

Ki-Board——用 Kiro 两天从想法做到成品,连那只幽灵吉祥物都没落下。
但真正让这个 swarm 转起来的是什么——这才是全文的题眼。八个 agent 同时往一个项目里敲,那不是团队,是车祸现场,除非它们之间共享着某样东西。在 Kiro 这个 demo 里,那样东西就是 spec:一份写下来的、唯一的事实源,每个 agent 都从它读、又写回它。规范驱动开发在这儿不是锦上添花的提效手段,而是那面承重墙。把这份共享的 spec 抽走,这支队伍立刻变回八个各改各文件的陌生人。真正指挥这支乐队的,不是模型,而是模型脚下那份共享的、结构化的记录。
所以,创造正朝两个方向被工业化——一个操作者横向铺开成一支队伍,整条生产栈又纵向坍缩进一双手——但这一切能成立,全靠底下有一层地基把这些 agent 拢在一起。事实证明,"造东西"是这三道前沿里最容易的一道。最后一道难得多:不是去感知世界,也不是在世界里造东西,而是行动——把智能装进一具身体,放它出去。
行动:把智能装进身体
第三道前沿,围观的人最多。在写着 Physical AI 和 Agent for Industries 的招牌下,宇树的人形机器人在灯光里伸手、抓握——身后屏幕打着一句"力控灵巧手,操作万物"。一只标价 ¥9,999 的 LinkerHand 灵巧手,冲着镜头比耶。一台自主移动机器人(autonomous mobile robot,AMR),在一圈积木搭的迷宫里慢慢找路。智元的人形、中联重科的自主机械也都摆在场内。智能,肉眼可见地在伸手够向一具身体。

AWS"Physical AI"展台上的宇树人形机器人——身后屏幕打着"力控灵巧手,操作万物"。
可在展台前站上十分钟,差距就露了出来。离真正的通用机器人,还远着呢——而差距最集中地卡在最难、也最没解决的那个部件上:手。一只现代人形机器人的手,是一丛执行器(actuator)堆出来的奇迹——特斯拉最新的 Optimus,光是手和前臂就塞了大约五十个执行器,而执行器占了整机物料成本的一半多。灵巧手算不过账,根子就在这儿:这样一只手,只有到了没人摸到过的量产规模才便宜得下来——所以桌上那只 LinkerHand,至今还卖一辆小电驴的价。

LinkerHand L20 灵巧手——标价 ¥9,999,却仍是这行最难啃的部件。
还有一层更深的原因,它有名有姓——莫拉维克悖论(Moravec's paradox)。那些已经能拿数学奥赛金牌的模型,抓一个没见过的物件,还不如一个三岁小孩稳。原来推理才是容易的那头;难的是手眼协调——在不确定里抓取、失了手还能找补——这种本事不像文本,没法从网上扒下来。所以真正能挣钱的机器人,都是"窄"的。IFR 数过,2024 年全球新装的工业机器人约 54.2 万台——绝大多数是单一用途的机械臂,一半以上装在中国;而地球上最成功的那支机器人队伍,是亚马逊已经过百万台的大军,搬的是料箱,不是大山。连最看多的人都认这个形状:摩根士丹利估计,到 2050 年约九成人形机器人干的还是重复、结构化的活,不是陪你聊天。

AWS 展台上,一台自主移动机器人在积木迷宫里找路——正是今天真正能落地的那种"窄"机器人。
而这里,正好绕回了我们的论点。让亚马逊那一百万台机器人变得有用的,不是一百万具聪明的身体,而是 DeepFleet——一个拿自家物流数据训出来、跑在 Amazon SageMaker 上的基础模型(foundation model),把整支车队的行进时间砍掉了约一成。真正值钱的那点智能,长在调度层(scheduling layer),不在那只爪子上。而全场最说明问题的展台,根本不是哪家机器人厂商——是德勤。我的老东家,一家咨询公司、最被人头绑死的那种生意,却在上海立了一支约二十人的物理 AI 团队:不做机器人,而是把造机器人的和要机器人的两头接起来,再靠自己的客户网络,推着方案落地。当一家四大之一押注于"做那层连接"、而不是"做那台机器",它其实在告诉你:稀缺的那一层,到底在哪儿。

德勤亚太物理人工智能展台——一家咨询公司,把自己摆成了那层"连接组织",而不是那台机器。
所以,哪怕到了最物理的这道前沿,规律依旧成立。身体,是慢的、窄的、贵的那部分;真正把一台"窄"机器人变成能用的系统的,是它底下那一层——调度、数据、连接。三道前沿——感知、创造、行动——每一道追到尽头,都落在同一个不性感的地方。是时候别在展厅里转了,去看看撑着这一切的那层地基。
撑住这一切的地基

在上海的台上——我身后那张幻灯片,正是这一节要讲的:一个产品,和它脚下的数据底座。
这,正是我跑到楼上去讲的东西。我在 HP 的团队做一个产品——Nova,一个管 PC 测试的平台——同时,也做它脚下那层数据底座。一年前,这层底座还是一套 Power BI:报表和数据处理糅在同一个工具里,原始数据被锁在里面出不来。复杂报表刷新一次要四到六个小时,底层数据也没法干净地取出来给别的用途。于是我们把它搬走了:从 Power BI,搬到 S3 上的 Amazon Athena 加 Apache Iceberg,用 Glue 做数据接入,用 Step Functions 和 EventBridge 编排管线。整个过程里,报表照常跑——同样的看板、同样的刷新时间——我们却把它底下的引擎换掉了。底座换了血,上面几层却毫无察觉。而“把数据从旧系统里解放出来、让 agent 够得着”这道题,正是亚马逊云科技在这届峰会上点名的、agent 时代的核心挑战——过去这一年,我做的恰好就是这件事。
这一换,换来的不是一张更快的报表,而是"选择权"。同一份底座,如今用同一批表喂三种很不一样的负载:老的 BI 报表,要的是稳定一致的聚合;机器学习训练,要的是可回溯的原始明细;还有——我那天站上台的缘由——一个 AI agent。我们管它叫 Compass:你用大白话问一句,它就从数仓(data warehouse)里把答案捞出来。让这个 agent 转起来的窍门,既平淡又关键:我们把 Athena 包成了一个工具——一个"Athena adapter"——于是 agent 既不写 SQL,也不必关心数据存在哪儿。它只管按一个稳定的约定去调用工具,剩下的交给底座。上面的模型随时能换,下面这个约定不能。
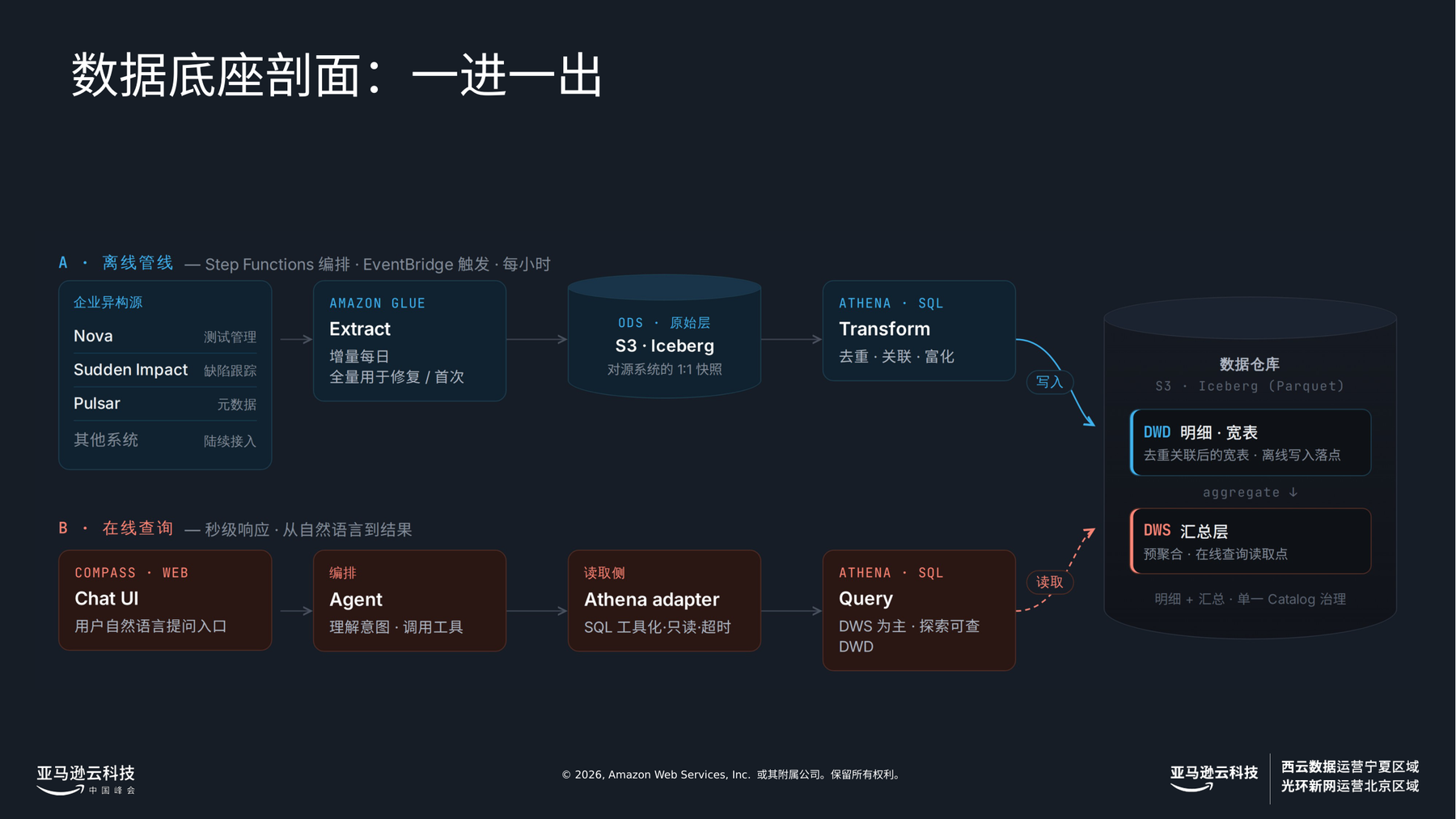
数据底座剖面,取自我的幻灯片:上半是每小时的离线管线(AWS Glue → S3/Iceberg,分层 ODS → DWD → DWS);下半是在线链路——一句自然语言从 Compass Chat UI 出发,经编排 Agent 和只读的 Athena adapter,落到一次 Athena 查询。
下面这个想法,是我最想让在场的人带走的,而且它比我那次迁移大得多。到了智能体时代,"数据底座"这四个字,得装下比从前更多的东西。老定义——你的业务数据、系统数据、那些企业表——依然是原料,也依然最重要。但一个真正在跑的 agent 系统,会生出第二种同样吃重的数据:它自己运行时吐出的"尾气",每一段推理、每一次工具调用、每一个烧掉的 token;它还需要第三种,来决定上面这一切到底可不可信:评估,那些告诉你 agent 到底对不对的 benchmark 和打分。原料、仪表、质检——一座工厂三样都得有,一座为 agent 而建的数据底座,也一样。把“质检”单拎出来当第三块板,也不是我一个人的执念:这届峰会上,亚马逊云科技就发布了《企业生产级智能体开发指南》白皮书,把“评估驱动”摆成了开发生命周期里正经的一环。质检这件事,正从“事后补票”变成“行业共识”。
注意,这会让整幅图变个样。底座不再只是 agent 去取数的地方;它同时也是 agent 在喂的东西。还记得几层楼下那辆车吗——它把每一句自己处理不了的请求,都变成了回头重训它的数据。那是同一条回路,放大来看:agent 消费底座去行动,又产出数据——轨迹、结果、评估——回头把底座喂厚,底座再让 agent 更强。keynote 自己也讲了个飞轮——模型能力和 Agentic 工程,互相把对方往上推——而且把它摆在了整个故事的正中央。但我说的是另一个飞轮:agent 和它甩出来的数据,彼此咬合、互相转动。这第二个飞轮,落到实处,才是整台机器——而它转起来要的那层数据,大多数团队还没建。
这就是为什么我反复管这层叫护城河。算力是租来的,模型在趋同;唯独属于你的数据——你的业务记录、你的 agent 攒下来的行为、你一点点磨出来的评估——会复利,而且没有对手能克隆。它是这一整摞里唯一一块贴着你业务长、还越用越值钱的板。这点 AWS 自己也画得很明白:在它那张蓝图里,数据是单独标出来的一层,就垫在 agent 底下,做它们的地基。我那天在台上的说法更直接——智能体时代,数据底座决定了它上面一切的天花板。把钱投到地基上,就是投到你还没想到的每一项 AI 能力上。
而一旦你信了这个,剩下唯一要紧的问题,就不是"要不要建底座",而是:怎么建一座能让整家公司都站上去的底座。
从一座地基,到一个平台
老实说,一支团队的地基,不够。我演讲的第三幕,讲的就是接下来这步:把一个项目的数据底座,变成整家公司都能站上去的共享平台。该不该走这一步,算笔账就清楚了。当每支团队都各建一层数据,你最后会得到同一批表、被算出三种口径,在三个会上吵来吵去。把它们收敛到一个平台上,三件事就会发生——也正是 keynote 真正说对的那三件。
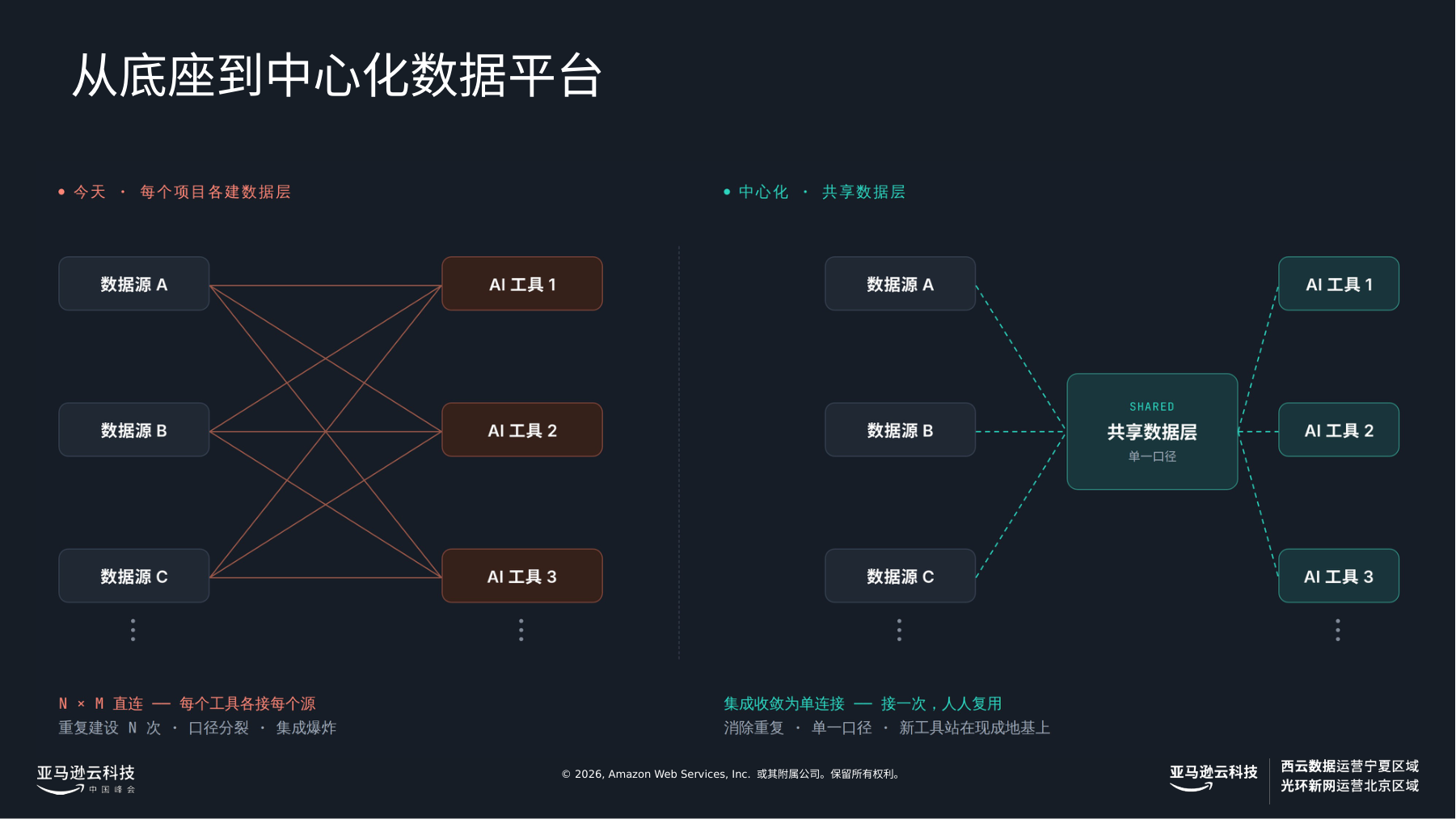
第三幕的核心一图,取自我的幻灯片:左边是今天——每个项目各建数据层,N×M 条直连,重复建设、口径打架、集成爆炸;右边是收敛之后——一个共享数据层、单一口径,新工具直接站上现成的地基。
第一,不再重复造:一条管线、一个数仓,而不是 N 支团队各维护各的。第二,你有了单一口径(single source of truth)——每个指标只有一个权威定义,"活跃用户"在财务和在产品那里指的是同一件事,跨团队的扯皮到此为止。第三,也是会复利的那件:你之后每加一个 AI 工具,上线都更快、花钱都更少,因为它脚下那层地基本来就有了。平台被用得越多,在上面再搭东西就越便宜——产出,又一次随基础设施增长,而不是随人力。

亚马逊云科技把 Bedrock AgentCore 摆成「智能体平台」——是把 agent 那一层做成了产品。我演讲的第三幕,讲的则是它底下那层的平台:那份 agent 都要跑在上面的数据。
这也是治理从“成本”变成“助推”的地方。keynote 有句话说得好:信任和治理是加速器,不是刹车。智能一旦被工业化,一层没人治理的数据,就不再是你慢慢管的风险,而是一座没有质检的工厂——以机器的速度,批量出残次品。血缘(data lineage)、权限、可审计、一个统一的 catalog——正是这些,才让你敢把 agent 放出去。而平台,也恰恰是"demo 演得漂亮"和"系统真能上生产"之间的那道线。
这一切都不是白来的,演讲里也讲明了。把一切收敛到一个批处理底座上,意味着你的数据新鲜到小时、到天,而不是到毫秒;你拿实时,换来了成本、灵活和可演进。这是一次清醒的取舍,不是疏忽——而对那些真正要紧的负载来说,"可治理、可复用"胜过"即时"。赢下未来十年的,不会是招了最多工程师、买了最大模型的团队,而是那些把地基修得最好、又把它治理得足够好、好到能让所有人都上去盖楼的团队。
在六楼,往回看

峰会中庭——两天的机器人、agent,和楼上那场安静的分享。
这场迁移,我自己也小小地经历了一遍。几年前,我团队的活儿是做看板;今天,是给一支 AI agent 队伍铺它们要跑的数据地基。那块"感觉有价值"的地方,一直在往下沉——从报表里,沉到报表底下的地基里。这一整场峰会的故事,浓缩进一个人的职业生涯,差不多就是这样。
楼下,你能看到同一场迁移。我的老东家德勤——一家把"人的专业"按小时卖了一个半世纪的公司——这次来峰会,卖的不是机器人,而是把自己摆成"造机器人的"和"要机器人的"之间那层连接组织。当地球上最被人头绑死的生意,都开始围着基础设施重新站位,这风往哪儿吹,就很难看不出来了。
但这都不意味着人会消失。工业化没有终结劳动,它只是把劳动挪了地方——从织机挪到车间,从纱锭挪到系统。AI 这一版也在挪:从敲代码,挪到定义该造什么;从跑查询,挪到拥有那份大家都来查的数据;从亲手干活,挪到搭起、并治理好那层让活儿在上面跑的地基。那个稀缺又值得站上去的位置,不再是活儿本身,而是它底下那层地基——我此前也论证过,这些年,"资深"二字本来就在朝这个方向走。
所以,看了两天机器人和 agent、又在楼上讲完那场安静的分享之后,我真正相信的是这件事:那些会感知、会创造、会行动的机器是真的,而且在飞快变强。但决定谁赢的问题,从来不是它们能变多聪明,而是——谁来铺它们脚下那层地基,那层把"智能"从一个 demo 变成一个产业的数据底座。聚光灯在楼下。答案,在楼上。