Introduction to SRead
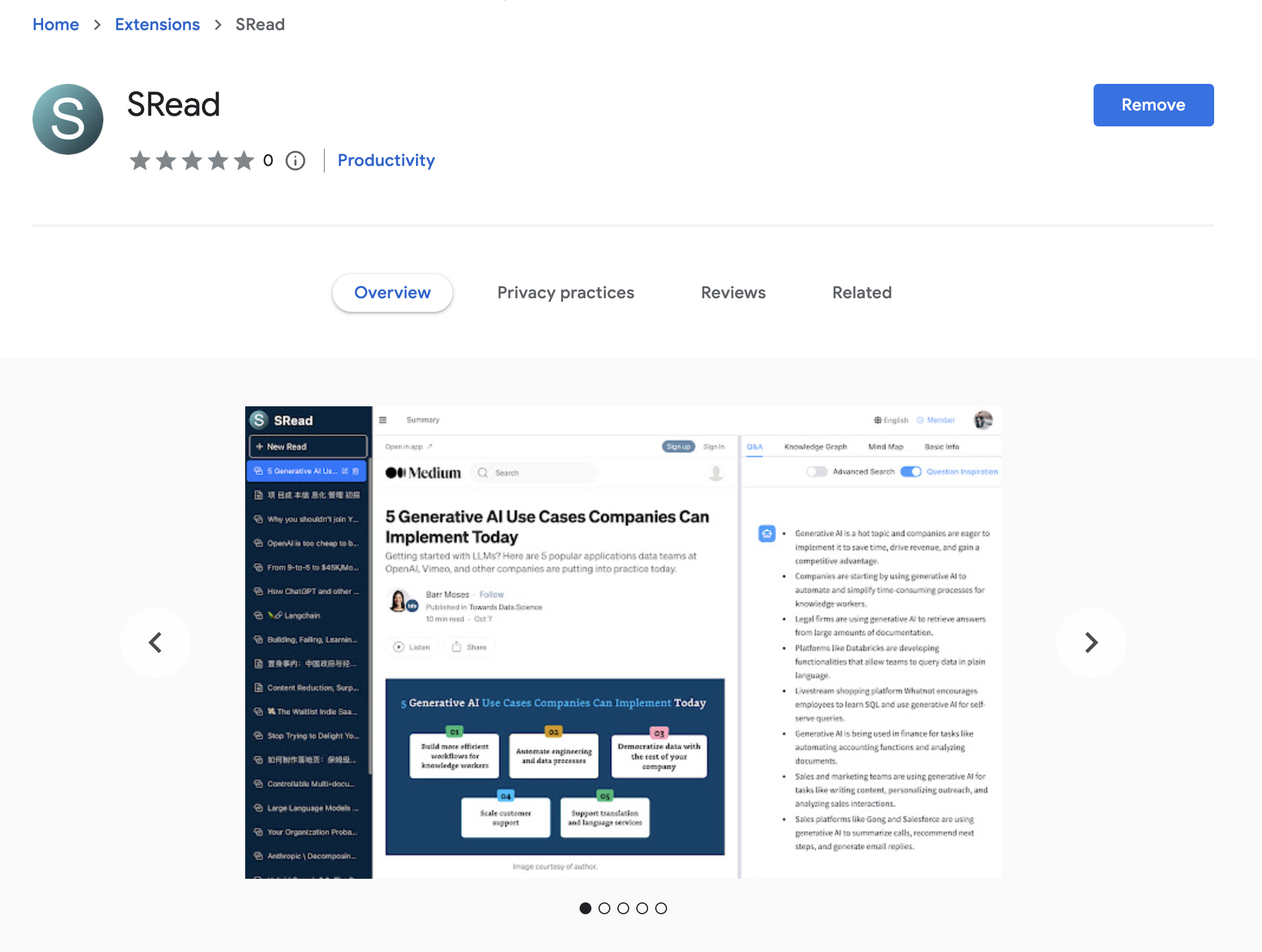
SRead is a smart reading assistant, whether you enjoy reading articles or viewing electronic papers, you can utilize SRead for assisted reading. SRead supports intelligent summarization, capable of extracting key information from the reading material and summarizing it; additionally, it can perform intelligent Q&A, answering any relevant information within the article. Moreover, SRead's mind map feature can help readers quickly grasp the outline of the entire piece.
Chrome Extension
The new Chrome extension of SRead brings a major upgrade to the browser reading experience. Once this extension is installed, users can directly enjoy all the features of SRead on Chrome browser without the need to download any additional applications. This extension includes a simplified toolbar, making it easy for users to quickly access the intelligent summarization, intelligent Q&A, and mind-mapping features while reading. Another important feature of this extension is that it can automatically recognize web page content, providing real-time intelligent assistance to users, making the reading experience smoother and more efficient.
Installation and Usage
Installing the SRead Chrome extension is very straightforward. Users first need to log on to the SRead website (https://sread.ai), and register/login with Gmail or WeChat. Then visit the Chrome Web Store, search for "SRead", and click the "Add to Chrome" button. Once the installation is complete, the SRead icon will appear on the toolbar, clicking the icon activates the extension and users can start using it.