On Generative AI Technology: Retrieval-Augmented Generation (RAG)

Introduction
Nowadays, generative AI applications are emerging like mushrooms after rain, overwhelming in their abundance. Large Language Models (LLMs) have become exceptionally popular with the release of ChatGPT and are a typical example of generative AI applications. However, LLMs have flaws. One significant problem is hallucination: for unfamiliar questions, LLMs fabricate answers that appear professional but have no factual basis. To solve this problem, many AI-based knowledge Q&A systems adopt Retrieval-Augmented Generation (RAG) technology, enabling LLMs to provide fact-based answers and eliminate hallucinations. This article will briefly introduce how RAG works in knowledge Q&A systems.
LLMs
To understand RAG, we first need to briefly understand LLMs. Actually, through extensive parameter training, LLMs can already complete many incredible NLP tasks, such as Q&A, writing, translation, code understanding, etc. However, since LLM "memory" remains at the pre-training moment, there will definitely be knowledge and questions it doesn't know. For example, ChatGPT developed by OpenAI cannot answer questions after September 2021. Additionally, due to the existence of hallucinations, LLMs appear very imaginative but lack factual basis. Therefore, we can compare LLMs to knowledgeable and versatile sages who can do many things but have amnesia, with memories only staying before a certain time and unable to form new memories.
To help this sage achieve high scores in modern exams, what should we do? The answer is RAG.
RAG
RAG is not new technology. As early as May 2020, before LLMs became widespread, RAG models were proposed for handling knowledge-intensive NLP tasks. Today, RAG has become very important technology in AI-based applications like knowledge Q&A and document retrieval.
Returning to the previous question, if we want LLMs to achieve high scores in exams, how should we do it? What is RAG's principle? The answer is actually simple: when LLMs encounter new questions, we take out chapters from textbooks related to the questions for LLMs to see. After seeing them, LLMs will derive answers based on their understanding combined with relevant chapter content. The generated answer will be fact-based (from textbooks), no longer nonsensical. Yes, this is exactly like open-book exams! This is RAG's principle.
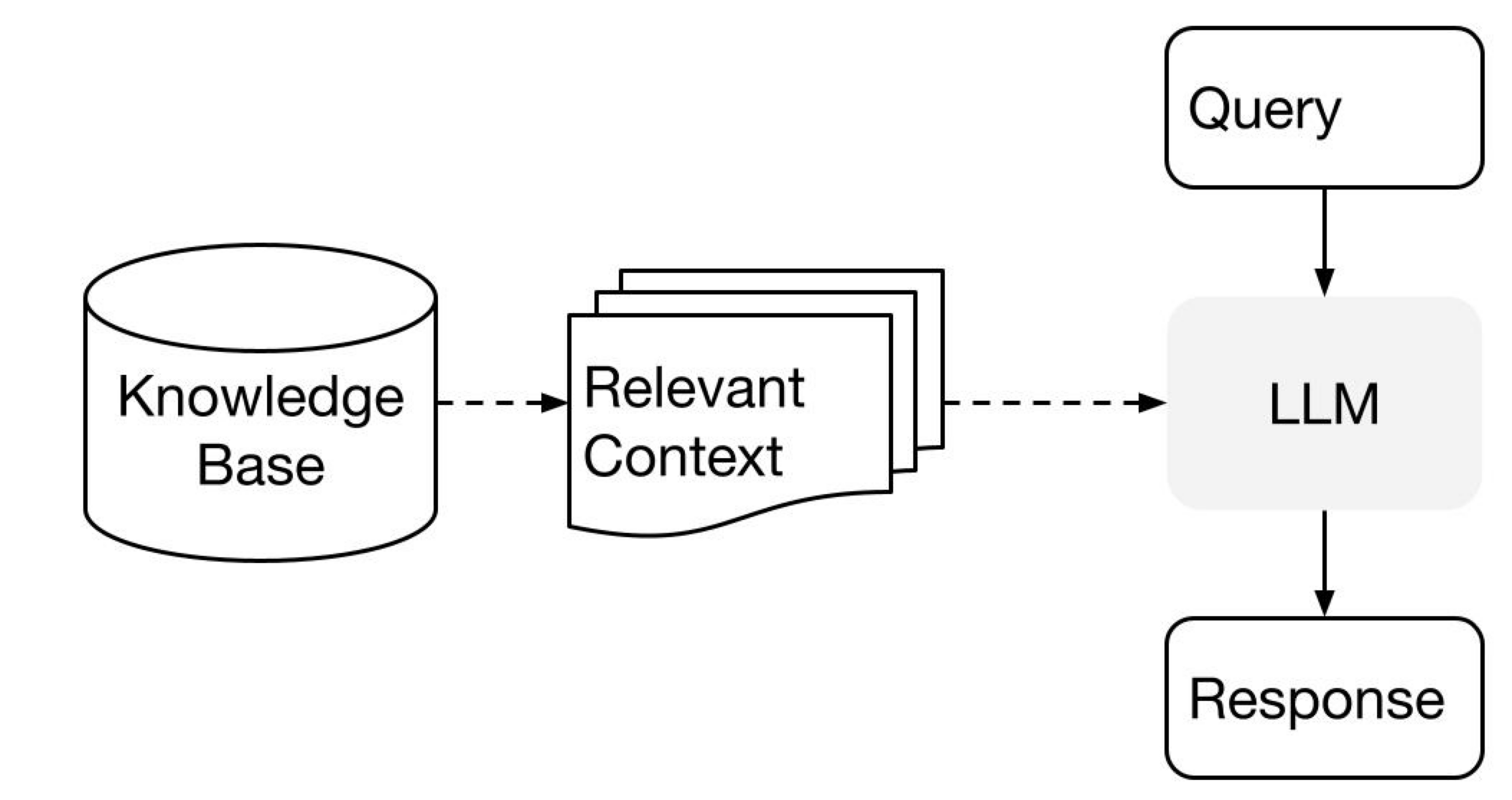
The diagram below is a typical knowledge Q&A workflow. When a query comes in, the system extracts relevant context from the knowledge base, then feeds both the question and context to the LLM, letting the LLM judge and answer the question autonomously, generating a response.
Embedding
We've introduced LLMs and RAG's simple working principles, but how do we extract relevant context from the knowledge base? The technology behind this is embedding. Embedding sounds professional, but we can understand it figuratively. It's like we pre-index each chapter or paragraph of textbooks (knowledge base), marking them with various colors and symbols. When we need to answer questions, we find relevant chapter paragraphs from the marked index and extract them for answers. Isn't it simple?
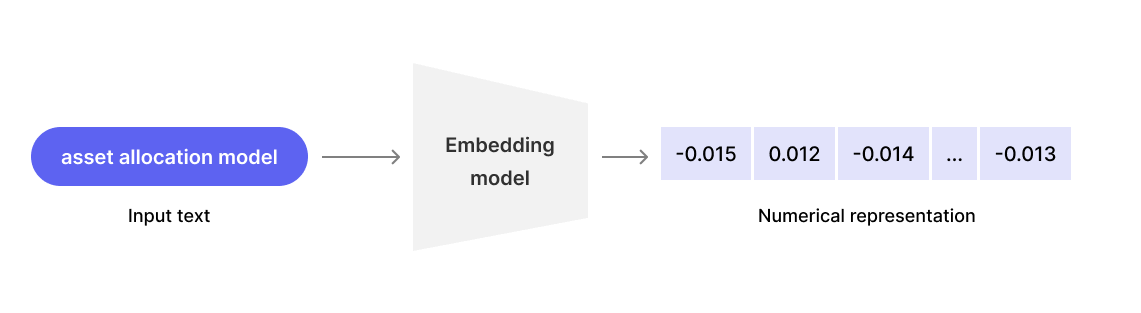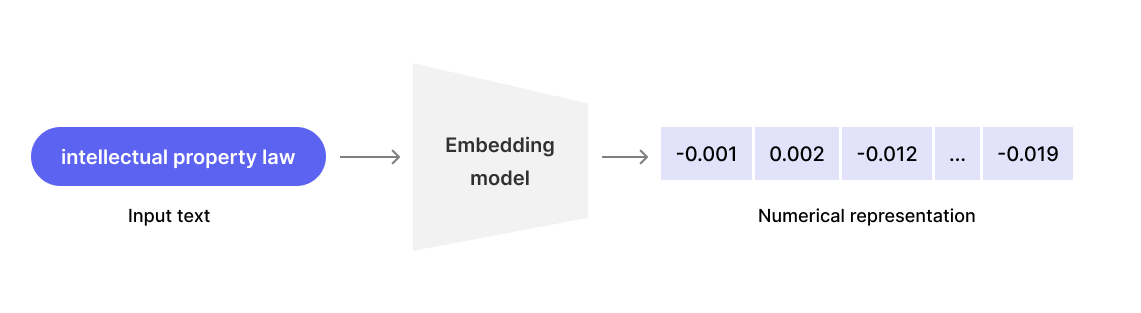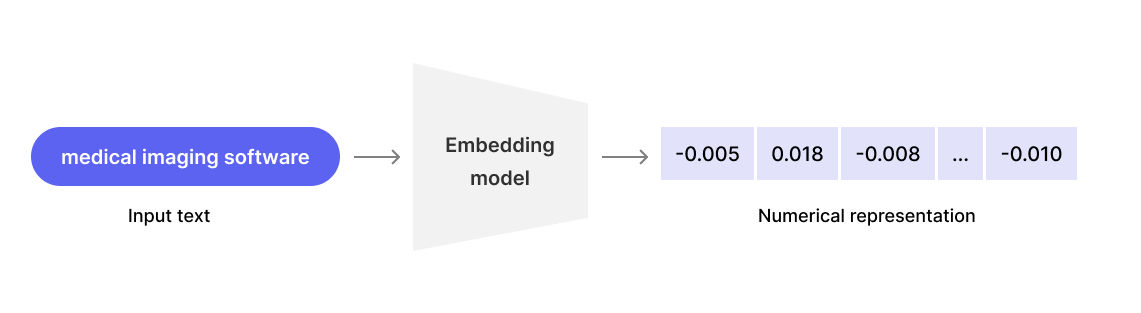
Of course, the essence of embedding technology is converting unstructured data (like text) into structured data (numerical matrices). Structured data is exactly what computers can process and understand. Not only text, but images, videos, audio, etc. can all be converted into computer-understandable structured data through embedding technology, which is also the basic principle of image search engines.
The diagram below shows inputting text and outputting numerical matrix representation.
Summary
Through simple analogies, we compared LLMs to knowledgeable but memory-impaired sages, RAG to open-book exams, and embedding to textbook markings, vividly illustrating core technologies of knowledge Q&A systems based on generative AI technology. My intelligent reading assistant SRead is also based on this technical framework, enabling AI to read and help readers answer questions related to articles, papers, and books. I hope this article helps readers further understand generative AI technology.

Community
If you're interested in my articles, you can add my WeChat tikazyq1 with note "码之道" (Way of Code), and I'll invite you to the "码之道" discussion group.
The intelligent reading assistant SRead is now online, beta address: https://sread.ai, welcome to try it.