Can Large Language Models (LLMs) Lead a New Industrial Revolution?

Introduction
"If our era is the next industrial revolution, as many claim, artificial intelligence is surely one of its driving forces." - Fei-Fei Li, New York Times
Nearly two years have passed since OpenAI's groundbreaking AI product, ChatGPT, was unveiled in late 2022. This powerful language model not only sparked widespread public interest in artificial intelligence but also ignited boundless imagination in the industry about the potential applications of AI in various fields. Since then, large language models (LLMs), with their powerful capabilities in text generation, understanding, and reasoning, have rapidly become the focus of the AI field and are considered one of the key technologies to lead a new wave of industrial revolution. Data from PitchBook, a venture capital data platform, shows that US AI startups received over $27 billion in funding in the second quarter of this year, accounting for half of the total funding.
However, while people are constantly amazed by the magical abilities of AI, they have also gradually realized some of the current problems with AI: hallucinations, efficiency, and cost issues. In the past period, I have more or less practiced AI technology based on LLMs in my work and projects, and I have a certain understanding of its principles and application scenarios. I hope to share my insights and experiences with LLM with readers through this article.
LLM Principles
To understand why ChatGPT, the LLM behind it, can give it a soul and make it seem almost omnipotent (answering questions, writing code, composing poetry, etc.), we must first understand its underlying principles. Due to space limitations, I will omit some technical details and introduce the basic principles behind the model in a more popular way.
Transformer
To introduce the principles of LLM, we have to mention the paper "Attention Is All You Need" published by the Google research team in 2017. The main contribution of this paper is the proposal of the Transformer architecture, which solves the problem of low efficiency of traditional sequence processing models (such as recurrent neural networks and convolutional neural networks) in handling long-distance dependency problems, becoming the basis for later LLMs. Transformer was originally used to solve the problem of language translation in the paper, and its effect was a level higher than that of traditional translation technology.
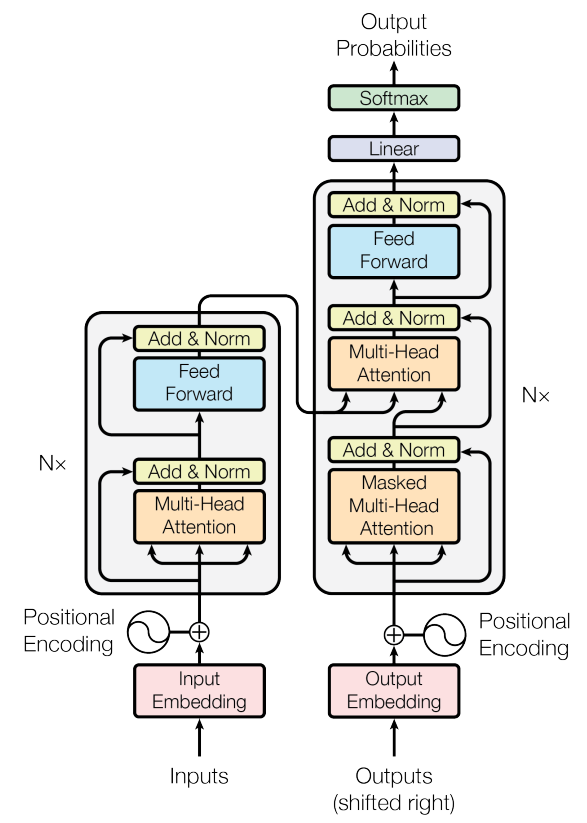
The architecture of Transformer is quite complex, but its core essence is to cleverly connect the words in natural language through multiple layers of neural networks, allowing the model to accurately judge the meaning expressed in the input sentence or dialogue by calculating the correlation between words, or attention. This provided a theoretical foundation for later large language models such as BERT and GPT.
GPT
As we all know, ChatGPT, which is very popular now, literally means GPT that can chat. The GPT here actually refers to the paper "Improving Language Understanding by Generative Pre-Training" published by OpenAI in 2018, which introduced the GPT model, which stands for Generative Pre-trained Transformer.
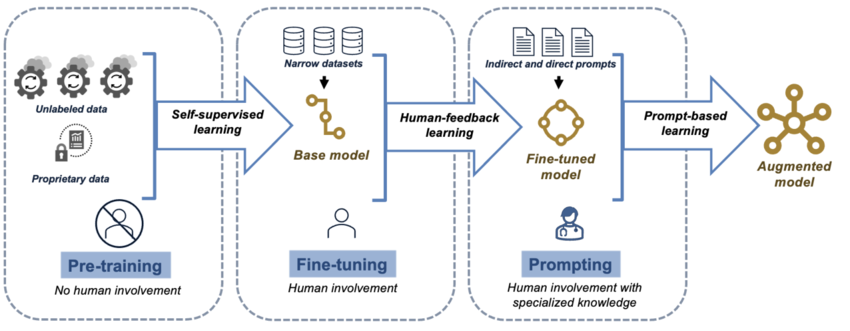
As can be seen, OpenAI researchers have gone further on the basis of Google's Transformer architecture, enabling it to complete more complex natural language tasks, such as reasoning, question answering, and text classification. The main improvement of the GPT model is that, compared with the basic Transformer, it does not require a large amount of labeled data, but mainly relies on unsupervised learning, also known as pre-training. The pre-trained model, which is pre-trained with a large amount of corpus data, can already generate natural language that is highly similar to human expression. In order to enable it to complete specific tasks, the pre-trained model is further trained on manually labeled data, a process called fine-tuning. The manually labeled data for fine-tuning is not much compared to unlabeled data, but this fine-tuning process is continuously iterative, and after multiple rounds of fine-tuning training, the GPT model has significantly improved performance in various natural language tasks, and also has strong generalization ability.
Generation Process
When we use conversational large language models like ChatGPT, Gemini, and Claude, you may notice that when you ask a question, the model always outputs one word at a time, just like we humans speak one word at a time. Therefore, if you ask ChatGPT to write an article for you, it will usually take a lot of time to output a complete answer due to the limitation of "speaking speed". The efficiency of LLM is usually limited by the rate at which it outputs words. This is actually the design principle of the Transformer architecture: when generating answers (also called inference), it always predicts and outputs the next word based on the words that have already been output, and at the same time, this newly generated word will also be used as the next round of prediction for the next word to be predicted, until the predicted word is a stop word. This process is called autoregression. Therefore, this output process has multiple prediction cycles, and the number of output words is the number of prediction cycles. For example, to output a 500-word article, the model will generate 500 rounds of predictions. From this, we can intuitively understand that the current output time of LLM is proportional to the number of output words, which will limit the response time of some AI applications. For example, if an application requires outputting an HTML code of a webpage, the user will have to wait several minutes for it to output all the keywords in the code.
Reasoning Process
The reason why large language models are called large is mainly due to the number of parameters in their underlying neural networks, which is usually on the order of hundreds of millions. For example, Meta's latest open-source large language model, Llama 3.1, has 8 billion parameters for its smallest model and 405 billion parameters for its largest model. Such a large parameter scale mainly comes from the number of layers of neural networks in the Transformer model and the number of neurons contained in each layer, and the parameter scale is the product of the two.
Why do you need so many parameters? We can simply understand it as the scale effect of neural networks: when the parameter scale of the neural network increases, the model's understanding and reasoning ability of language will improve accordingly. At present, AI researchers have no way to accurately understand this scale effect with a few simple and elegant theoretical formulas like physicists, so the LLMs we see now can basically be regarded as "black box models", so that researchers ponder: "It works. But why...".

However, some scholars have been trying to understand the principles behind the emergence of intelligence in large language models. In the review paper "Towards Uncovering How Large Language Model Works: An Explainability Perspective", various laws of the emergence of intelligence in LLMs are expounded. Some interesting examples: the shallow neural networks of large language models (closer to the input end) can learn simple concepts, while the deep neural networks (closer to the output end) can learn more complex and abstract concepts; large language models will go through an "enlightenment" (Grokking) process, that is, after continuous overfitting, they can suddenly accurately understand most meanings, thus achieving the result of knowledge generalization (isn't this very similar to our "learning by analogy" process?).
LLM Problems
After introducing some basic principles of large language models, we can review some of the current problems with large language models and how to mitigate these problems in AI applications.
Hallucinations
LLM hallucinations are a problem that has been criticized since the launch of ChatGPT. To put it simply, LLMs can often "talk nonsense with a straight face". The main reason is that when LLM generates text, it is not based on real understanding, but on statistical probability to predict the next word. Therefore, when the model has not seen certain specific contexts or information in the training data, it may generate content that seems reasonable but is actually wrong.
To alleviate the problem of hallucinations, researchers have proposed a variety of methods, and the current mainstream methods are retrieval-augmented generation (RAG), fine-tuning, and agents. These methods can effectively reduce the occurrence of hallucinations by introducing external knowledge, optimizing model parameters, and guiding the generation process. For readers who are not familiar with RAG, you can refer to my previous blog posts "A Brief Talk on Generative AI Technology: Retrieval-Augmented Generation RAG" and "AI in Action: Using Langchain to Build Efficient Knowledge Question Answering Systems".
Efficiency Issues
Although LLMs have powerful understanding capabilities and the ability to generalize, their output is based on a word-by-word (Token by Token) basis due to their Transformer architecture. Therefore, the output efficiency of LLM is largely limited by its actual Token output rate. In addition, the computational complexity of the model increases quadratically with the increase in input length, which leads to a significant decrease in efficiency when processing long texts.
Especially for agent applications, which usually require multiple LLM interactions, their execution efficiency is often limited by the LLM output efficiency. If the prompt engineering requires the LLM to output long sections of text, it will greatly reduce the response time of the agent application. Therefore, for agent application developers, it is necessary to strictly control the output text length of LLM, which can effectively improve the execution efficiency of the agent.
Cost Issues
Although the cost of large language models is gradually decreasing with technological advances, cost remains an important consideration factor. For LLM AI application developers, the cost billing model will depend on the type of LLM service they adopt. Here are the current mainstream LLM service models.
- LLM API Services: Since the release of ChatGPT, LLM service providers such as OpenAI and Anthropic have offered API services to support AI application developers to customize and develop various applications. Their billing method is mainly based on the number of tokens consumed, which is the length of the LLM input and output text. Taking OpenAI's GPT-4o model as an example, if you want to use it to develop an intelligent crawler application and let it analyze a medium-length webpage (20-50k tokens) and extract structured data, it will roughly cost 0.2-0.5 US dollars (approximately 1-3.5 RMB). Under this billing model, the higher the usage, the higher the cost, making it more suitable for small-scale users and startups.
- Self-built LLM Services: For enterprises that need to use LLM on a large scale, self-built LLM may be more cost-effective. The cost of self-built LLM mainly comes from purchasing graphics cards (GPUs), server maintenance, and power consumption. The high-performance requirements of graphics cards and the power consumption caused by long-term operation are the main cost sources. By using techniques such as model compression, quantization, knowledge distillation, and distributed computing, the demand for computing resources and power consumption can be effectively reduced, thereby reducing costs. Due to the availability of many excellent open-source models on the market, such as Meta's Llama and Mistral AI's Mistral, developers can directly download and deploy them for use, only needing to focus on the hardware (graphics cards and servers) required to run the LLM.
LLM Applications
At the beginning of the emergence of large language models, they were mainly used in classic natural language processing (NLP) application scenarios such as knowledge question answering, text summarization, and language translation. However, as people continue to delve into and explore, they have discovered that LLMs can do more unexpected things, such as writing code, data analysis, and task planning.
Chatbots
Among the mainstream LLM applications, the main ones include various intelligent question-answering chatbots. ChatGPT itself was originally a comprehensive chatbot. The various "Chat with XXX" AI applications that emerged later are also enhanced chatbots based on large language models. Compared to basic chatbots, their additional functions lie in their ability to conduct question and answer sessions based on uploaded documents (such as Word, Excel, PDF) through RAG, as if helping you "read" long articles and improve reading efficiency. The SRead I developed belongs to this category of applications.
These chatbots have wide applications in multiple fields:
- Customer Service: Automatically answer customer frequently asked questions, provide 24/7 support, and reduce the workload of human customer service.
- Education: Serve as virtual tutors to help students answer questions, provide learning advice and resources.
- Medical: Provide health consultations, symptom analysis, and medical advice, assisting doctors in diagnosis.
- E-commerce: Help users find product information, recommend products, and process orders.
Assistant Applications
Assistant applications utilize the powerful natural language processing capabilities of LLMs to help users improve efficiency and accuracy in various tasks. These applications can cover multiple areas, such as programming, office work, and writing.
- Programming Assistants: Such as GitHub Copilot and JetBrains AI Assistant, can automatically complete code, generate functions and classes, and even help debug and optimize code based on user input code snippets or comments, thereby significantly improving development efficiency.
- Office Assistants: Such as Microsoft 365 Copilot, can provide intelligent suggestions and automated operations in document editing, data analysis, schedule arrangement, and other office tasks, simplifying workflows.
- Writing Assistants: Such as Grammarly, can help users refine text, check grammar, generate content, and optimize structure, improving writing quality and efficiency.
These assistant applications, through natural language interaction with users, provide personalized suggestions and automated solutions, significantly improving user work efficiency and experience.
Agent Applications
At present, I believe the most promising application scenario for LLMs is automation, that is, utilizing the thinking capabilities of LLMs, such as reasoning, planning, and decision-making, combined with tools that can operate on the real world, to accomplish automated tasks. Such systems that can "think" and automatically execute tasks are called agents.
Agent applications are a popular research direction in the field of artificial intelligence. Both research institutions and startups are dedicated to developing agents that can create practical commercial value. Compared to training and tuning large models, developing agents has cost advantages. It does not require a large amount of hardware and data resources, and it is easier to implement and generate value in actual commercial applications, making it have a higher ROI.
From a fundamental perspective, the aforementioned "Chat with XXX" applications and Copilot applications can be considered simple implementations of agent applications. They simply process the user's input text according to specific prompts or pre-set standard procedures (such as RAG), thereby realizing their corresponding functions. The agent mentioned in this section generally refers to an agent that can perform complex tasks through a certain degree of thinking.
Regarding the theory of LLM agents, a relatively classic article comes from Lilian Weng, a researcher at OpenAI, titled "LLM Powered Autonomous Agents". In the article, the author proposes the basic framework of LLM agents. A complete agent needs to include three components: planning, memory, and tool use.
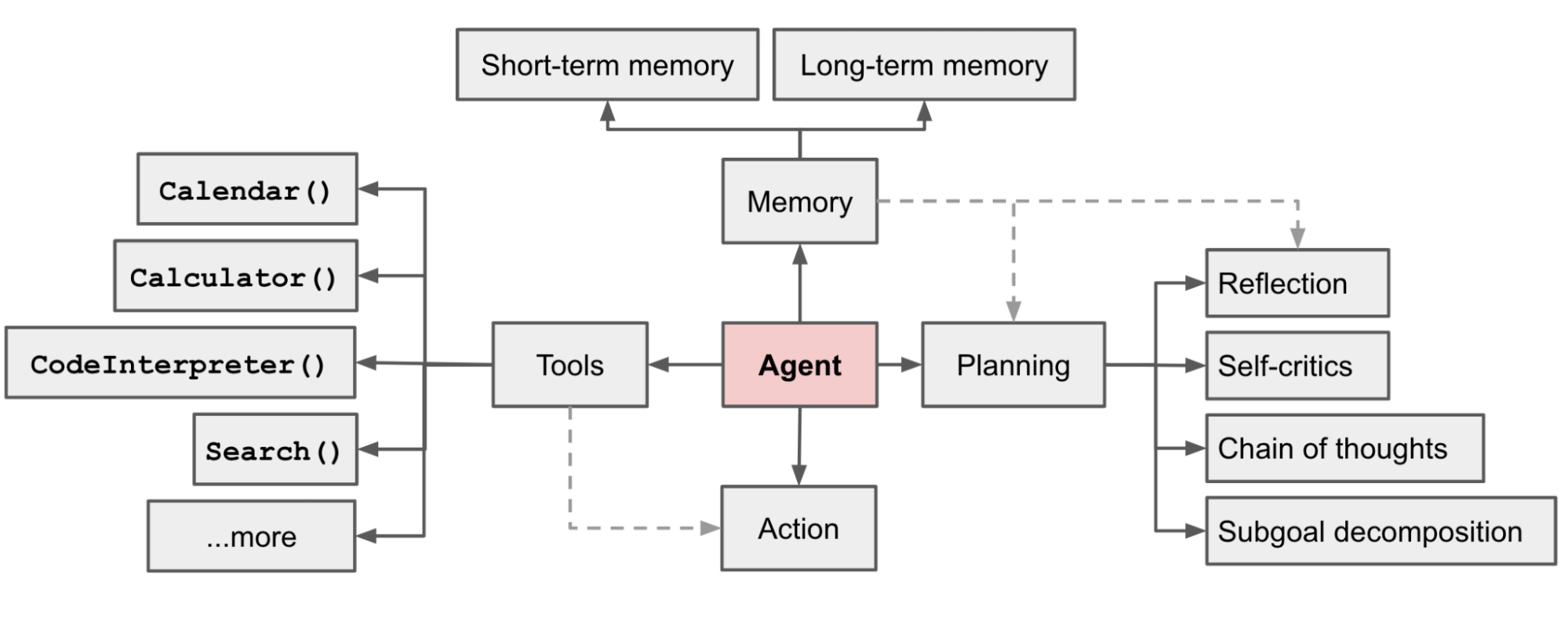
- Planning: Agents can use methods such as chain of thought (CoT), self-reflection, and ReAct to decompose complex problems into multiple simple problems and then divide and conquer.
- Memory: Agents can adopt different strategies for different types of memory. For example, short-term memory can be placed in the limited-size LLM context, while long-term memory is stored in more scalable vector databases.
- Tool Use: Agents can call external tools or APIs to complete specific tasks. For example, agents can use search engines to obtain the latest information, call calculators to perform complex calculations, access databases to query data, or even control robots to perform physical operations. For example, OpenAI's Function Calling is a standard framework for agent tool use, allowing developers to define functions (tools) that the agent can call, allowing the LLM to decide which tool to use, how to use the tool, and the returned data from the tool can be added to the memory for further use by the agent.
In the past period, I have developed intelligent crawler and data analysis agent applications in my work projects using LLMs, attempting to implement them based on the current agent theory. However, in practice, I found that the basic agent framework mentioned in Lilian Weng's article is not necessary. LLMs are already smart enough to give accurate answers without needing to "verbally" explain their reasoning behind their behavior. This is very similar to System 1 in Daniel Kahneman's "Thinking, Fast and Slow", where the brain can make intuitive judgments based on the environment. The reason behind this may be that the process of agents completing specific tasks (e.g., extracting XPath from webpages, aggregating data using which fields) may not require very complex thinking, and they only need to output necessary information without making too much explanation. This implies that the tools in agent application design need to be as simple and clear as possible.
Due to space limitations, I have only touched on the topic of agents in this section. I will write a separate blog post to supplement the content related to LLM agents in the future.
Conclusion
Large language models (LLMs), as key technologies in the current AI field, have demonstrated powerful capabilities in text generation, understanding, and reasoning. Whether in office collaboration, content creation, customer service, or more complex agent applications, LLMs have gradually penetrated into various industries, beginning to change our ways of working and living.
However, despite the excellent performance of LLMs in some application scenarios, their issues in efficiency, cost, and model hallucinations still need to be further addressed. At the same time, how to better combine the reasoning capabilities of LLMs with practical operation tools to develop more intelligent and automated solutions is also a future research and development direction.
It is worth mentioning that during the process of writing this article, I also used writing assistants to assist in writing part of the content. Perhaps you can guess which parts were created with the help of AI?