Spec-Driven Development: A Systematic Approach to Complex Features

Introduction: The Challenge of Complex Feature Development
Every developer knows the feeling of staring at a complex requirement and wondering where to begin. Modern software development increasingly involves building systems that integrate multiple services, handle diverse data formats, and coordinate across different APIs. What appears straightforward in initial specifications often evolves into intricate webs of interdependent components, each with their own constraints and edge cases.
This complexity manifests in several common development challenges that teams face regardless of their experience level or technology stack. Projects frequently suffer from scope creep as requirements evolve during implementation. Developers spend significant time explaining context to AI assistants or team members, often repeating the same architectural constraints across multiple conversations. Technical debt accumulates as developers make hasty decisions under pressure, leading to systems that become increasingly difficult to maintain and extend.
For a deeper exploration of how complexity emerges and accumulates in software projects, see my previous analysis: Why Do We Need to Consider Complexity in Software Projects?
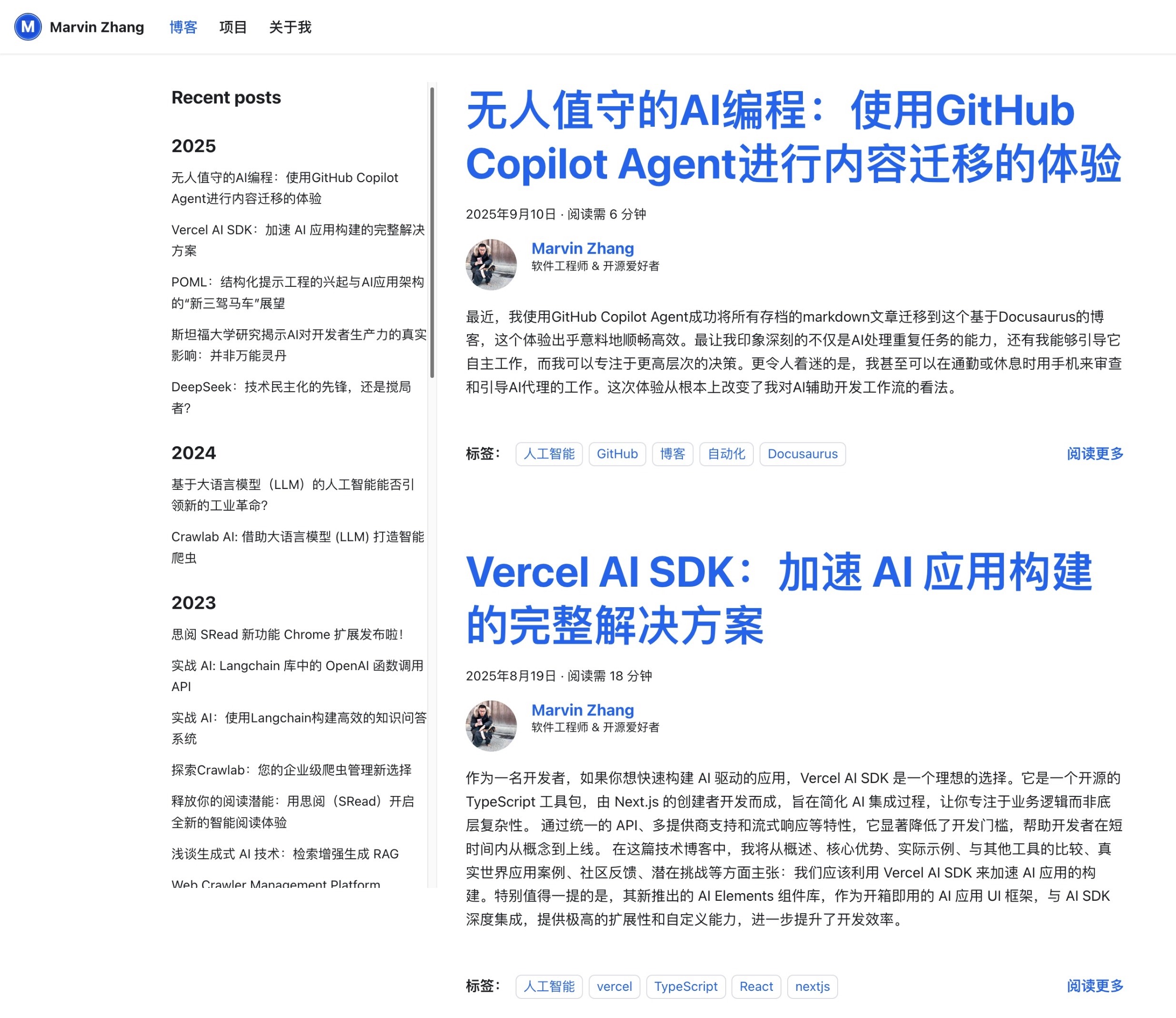 Figure 1: Migration results overview (Chinese)
Figure 1: Migration results overview (Chinese)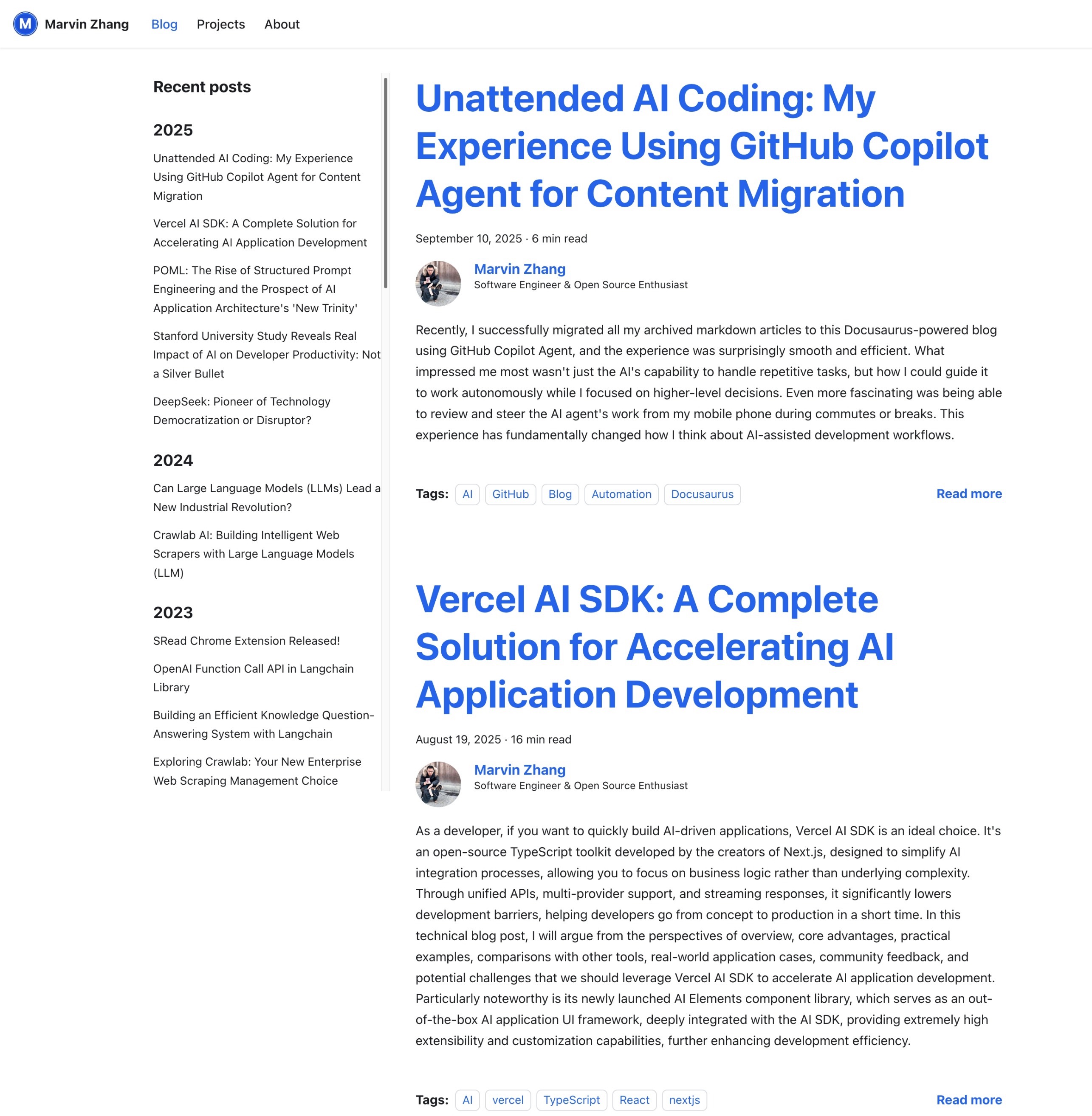 Figure 2: Migration results overview (English)
Figure 2: Migration results overview (English)